
Analyzing Qualitative User Data at Enterprise Scale With AI: The GE Case Study

Summary: Deriving UX insights from masses of qualitative user data is a challenge. GE’s innovative use of AI in analyzing support tickets improves usability and adds significant business value by optimizing resource allocation. Computer-assisted sifting of individual user comments humanized the heaps of data.
Customer support requests are a treasure trove of user insights. People only contact support if they have a problem with your software or service, so any support question is a sign of one or both of the following:
The system is too complicated, so users can’t understand it without help.
The user assistance is inadequate because people couldn’t find (or understand) the instructions independently.
Support requests help you prioritize rework efforts to improve both the system and its assistance in the places where improvements will have the most significant effect. But how do you make sense of hundreds, let alone thousands of tickets? AI rides to the rescue, as demonstrated by a new case study from General Electric (GE).

You want data-driven design decisions, but with qualitative data from multiple sources flooding your systems, how do you glean actionable insights? (“Too much data” by Midjourney.)
According to Wikipedia, GE is one of the world's largest companies, with about 172,000 employees and USD $77 billion in annual revenue.
I recently talked with Erin Gray, the UX Lead and Conversational Architect for People Operations Technology at GE Corporate, to learn more about GE's use of AI to operationalize the insights from masses of user support requests. As implied by Erin’s title, her department supports the company’s employees with internal HR information. However, the lessons from the project apply to anybody with many support requests, whether the users are buying customers seeking product support, or staff members needing internal help with employment matters.

Erin Gray is UX Lead and Conversational Architect for People Operations Technology at GE Corporate.
A note about the illustrations in this article: GE has generously provided sanitized data visualizations of some of its internal AI project functionality. Since the data is sensitive and concerns internal employee matters, the screenshots have been altered to illustrate the capabilities without disclosing confidential information. All data representations are hypothetical.
Bearing the Weight of High Inquiry Volume
Roughly half of GE employees are primarily English-speaking. For this population alone, Erin's department can receive up to 70,000 user inquiries monthly or somewhat less than a million contact points annually. No human could review them all!
Adding complexity, employees contact support through 5 main channels: computerized chatbot, human-supported chat, phone calls to support agents, support request forms, and employee feedback surveys. Each channel has its own data format, obstructing consolidated analytics across the total corpus of employee requests.
Inquiries handled by human support staff are notoriously expensive, providing an immediate business justification for reducing the volume of cases where employees feel the need to turn to support. Furthermore, even though human agents and chatbots record the cases they handle, they will not always classify them consistently, muddying metrics and analyses.
s Nielsen’s Third Law of AI states, AI scales, humans don’t. It’s a child’s work for a computer to read through millions of records and compute trends across the years. But traditional software can’t make sense of messy natural-language records in multiple data formats and encoding schemes. Recognizing the potential opportunity, Erin pitched and gained buy-in to lead the AI-driven project that would enable measuring and trending user inquiries within the combined GE service channels volumes.
AI-driven natural language processing solved the problem of cross-channel visibility and enabled actionable level prioritization of user needs. Erin and data scientist team member Sirisha Kondapalli developed a finetuned model, training the AI with human-classified sentences from the complete data set to allow it to differentiate between more and less important user statements.
One interesting lesson from this effort is that the size of the internal training set needed to improve the foundation model depends on the variability of how users voice a particular need. If your users’ needs are highly variable, a more extensive training set will be required to finetune AI for optimal performance. In contrast, a smaller training set is acceptable for less variable needs. To create the algorithm’s library, UX qualitative data analysis skills were crucial in identifying topic patterns and mapping language examples to user needs. Further process owner workouts were conducted to leverage expertise, validate mappings, and synthesize AI predictions for deeper meaning.
A further benefit of AI-driven analysis is that it’s source-agnostic, meaning that it can incorporate additional sources of user data, for example, if new service channels are opened in the future. Integrating disparate data sources with traditional software always requires an expensive and error-prone development project that introduces substantial delays in understanding the data. In comparison, AI is flexible to use on top of a multitude of given digital products and data sets.
Identifying Key Problems
Without AI help, it took too long to discover problem areas across channels where employees were having difficulty and turning to support in undue numbers. However, the AI analysis of the support inquiries had two immediate benefits for employee service:
It became possible to quantify the volume of employee needs across the 5 support channels. When there’s a spike in support volume about a particular issue, that problem can get priority to be fixed.
Trends analysis allowed the team to measure the effectiveness of such process improvement efforts. Did a supposed “improvement” actually work? If yes, the dashboard would show a drop in support volume for that problem. If not, the team could try a different solution.

The new system can visualize the total volume of user needs across the 5 support channels. (Screenshot courtesy of GE.)

This chart shows the benefits of visualizing how the volume of combined channel support requests stemming from a specific user need changes over a long period. We can clearly see the impact of implementing a change and thus conclude whether additional improvements would be required. (Screenshot courtesy of GE.)
Identifying individual problems so that they can be prioritized and tracked by volume is already an immense achievement. Even better, the AI can also identify co-occurring issues. Leveraging this capability, it became possible to understand where users were asking questions about two things within the same inquiry.
Realizing that specific problems happen together may inform better process design. At a minimum, co-occurrence can be supported by adding cross-references between the two issues to shortcut navigation overhead. Utilizing this same cross-reference capability, it also became possible to verify agent and chatbot classifications and understand the correlation with positive/negative survey volumes.
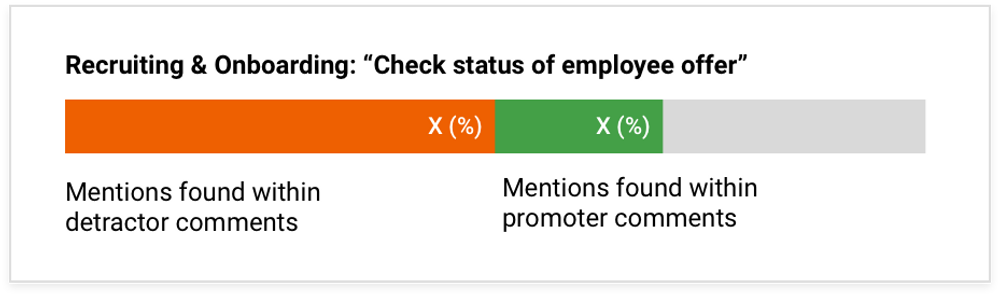

Co-occurring needs discovery visualizes cases where many users have encountered two different problems at the same time, meaning that there must be some relationship between the two that should be addressed. (Screenshots courtesy of GE.)
UX Process Improvements
It is much discussed within the user experience field how much AI can help us perform our human-centric tasks. The GE project provides examples where AI support benefited traditional UX processes.
In the discovery process, it was possible to focus staff time on the most critical content within the large volume of information collected from the users. The AI system was trained to eliminate less important text and showcase the more important text. This dramatically reduced the amount of plain reading required by staff to glean insights from support text.
When training the algorithm, it was important to work on a set of related needs rather than a singular need, as this helped avoid prediction conflicts and maximized the project team’s validation time with process owners. The team leveraged existing structured data containing groups of related needs, such as “Recruiting and Onboarding,” to narrow its focus. Typical sprints would include 10–15 new needs ; on average, it could take 5 hours to identify and train a given need from start to finish. Overall, about 5,000 unique excerpt examples were mapped to fully trained needs, and each need had an average of 150 mapped excerpt examples — though optimal performance was not entirely dependent on excerpt example quantity.
Various classification algorithms were initially explored for building the needs classifier, including Logistic Regression, Support Vector Classifier, and tree-based models such as Random Forest, Adaptive Boosting, Gradient Boosting, and XGBoost. Ensembles of the top-performing algorithms were then constructed to optimize performance, primarily using a bag-of-words approach. Transitioning into deep learning, experiments were conducted with word embeddings, Recurrent, and Convolutional Neural Networks, as well as fine-tuning BERT for text classification. However, two main challenges persisted throughout the experimentation: the models were primarily trained on “short” user-written text, and the available data was insufficient for deep learning. Ultimately, a Voting classifier comprising Support Vector Classifier, Random Forest, Extra Trees Classifier, and Gradient Boosting Classifier proved to be the most effective model.
Note that this AI classification doesn’t have to be perfect. It’s not as if AI is charged with picking out the one user quote from millions that will become the foundation for designing a new feature. All the AI does is concentrate the proportion of gold nuggets within the material a team or individual can realistically be expected to read during a discovery project.

An 1849er pioneer would have wanted to pan for gold in a river with a high concentration of gold. AI serves a similar purpose by selecting the user comments most likely to be valuable for the team, according to its training data. Not every comment chosen is gold, but many more of them are than would be present in a random sample. Image by Midjourney.
For journey mapping, it was possible to use AI analysis to pull quantified metrics of when users are asking specific questions. This provided the ability to quantify the user pain points and integrate them within a journey map sequence. This quantification also serves as a benchmark to compare the present-state journey map with future metrics after making changes.

A journey map can be augmented with a visualization of the volume of problems users encounter at the various steps of the journey. This helps prioritize efforts to improve the journey, first focusing on the most significant pain points. (Screenshot courtesy of GE.)
The AI could also extract and quantify the vocabulary that various employees use to refer to specific issues. This makes it possible to write support information in a user-centered language. Writing in the users’ language has always been a key usability recommendation.
Still, realistically, it has been hard to find out how many people in different job classifications talk about a broad spectrum of issues. The teams responsible for various support areas know what words employees use and what specific questions they have about the topic at hand. Thus, the AI analysis makes it possible for the first time to actually answer frequently asked questions instead of guessing what the FAQs might be.
AI Analysis Magnifies UX Work, Improving Delivered Quality
A common theme behind all these individual results from the GE project is that the AI analysis of immense volumes of free-form support data serves as a force multiplier for staff charged with improving the user experience.
AI makes it possible to understand at a macro level what’s happening across hundreds of thousands of individual user difficulties. This enables:
New discoveries along the famous lines of the needle in the haystack. AI is a super magnet that pulls the metaphorical needles to the surface where they can be seen.
Prioritizing resources to fix the biggest pain points first because now the issues can be quantified.
Tracking improvements (or lack of progress) over time.

With a giant haystack of qualitative data, how do we find the proverbial needle? AI analysis is a magnet that pulls the needle to the surface where we can see it. (Haystack by Leonardo.)
I am impressed with GE for committing resources to develop advanced technology to make life easier for its many employees across the organization. Too often, when employees are far from headquarters, their needs don’t get the attention they deserve, but AI technology allows the central support team to draw a helpful map of the manifold employee needs so that resources can be spent where they help people the most.
I thank Erin Gray for helping me understand her exciting project. My comments about the project are solely my responsibility, as are any inaccuracies in the above write-up.
More on AI UX
This article is part of a more extensive series I’m writing about the user experience of modern AI tools. Suggested reading order:
AI Vastly Improves Productivity for Business Users and Reduces Skill Gaps
Ideation Is Free: AI Exhibits Strong Creativity, But AI-Human Co-Creation Is Better
AI Helps Elite Consultants: Higher Productivity & Work Quality, Narrower Skills Gap
The Articulation Barrier: Prompt-Driven AI UX Hurts Usability
UX Portfolio Reviews and Hiring Exercises in the Age of Generative AI
Analyzing Qualitative User Data at Enterprise Scale With AI: The GE Case Study
Navigating the Web with Text vs. GUI Browsers: AI UX Is 1992 All Over Again
UX Experts Misjudge Cost-Benefit from Broad AI Deployment Across the Economy
ChatGPT Does Almost as Well as Human UX Researchers in a Case Study of Thematic Analysis
“Prompt Engineering” Showcases Poor Usability of Current Generative AI
About the Author
Jakob Nielsen, Ph.D., is a usability pioneer with 40 years experience in UX and co-founded Nielsen Norman Group. He founded the discount usability movement for fast and cheap iterative design, including heuristic evaluation and the 10 usability heuristics. He formulated the eponymous Jakob’s Law of the Internet User Experience. Named “the king of usability” by Internet Magazine, “the guru of Web page usability" by The New York Times, and “the next best thing to a true time machine” by USA Today. Before starting NN/g, Dr. Nielsen was a Sun Microsystems Distinguished Engineer and a Member of Research Staff at Bell Communications Research, the branch of Bell Labs owned by the Regional Bell Operating Companies. He is the author of 8 books, including the best-selling Designing Web Usability: The Practice of Simplicity (published in 22 languages), Usability Engineering (26,211 citations in Google Scholar), and the pioneering Hypertext and Hypermedia. Dr. Nielsen holds 79 United States patents, mainly on making the Internet easier to use. He received the Lifetime Achievement Award for Human–Computer Interaction Practice from ACM SIGCHI.
Subscribe to Jakob’s newsletter to get the full text of new articles emailed to you as soon as they are published.
GE's innovative use of AI is truly remarkable! It's impressive to see how technology can transform the user support experience, making it more efficient and user-centric. This is a great example of how data-driven decision-making can lead to better customer service. I'm also working on making the use of AI something relevant for UX researcher and I came up with Personai, an online tool enabling anyone to engage in meaningful conversations with personas built from real user research data. Do not hesitate to ask for a demo I'll be more than glad to gather your feedbacks on it 🙏 https://try.askpersonai.com/